This is intended as a brief guide to help you start monitoring your Juniper Mist infrastructure with Webhooks. This document is written to be descriptive of the webhooks process and methods to use, it is not intended to be a replacement for the API documentation (/api/v1/docs/Site#webhooks).
In any place where the API documentation contradicts this document, you should assume the API documentation is updated and accurate.
Introduction to Webhooks
The idea behind webhooks is that you define a webserver that can receive a notification when an event happens in the Mist environment. This event can be as simple AP disconnecting from the cloud, or as complicated as Marvis concluding that a cable is bad based on machine learning data.
When looking at other systems, other terms for webhooks can be “HTTP Notifications,” “user-defined HTTP callbacks”, or just “HTTP Posts.”
The important point for Webhooks with respect to Mist is that it allows the Mist infrastructure to push events to you when they happen, rather than requiring you to poll the Mist API every X interval.
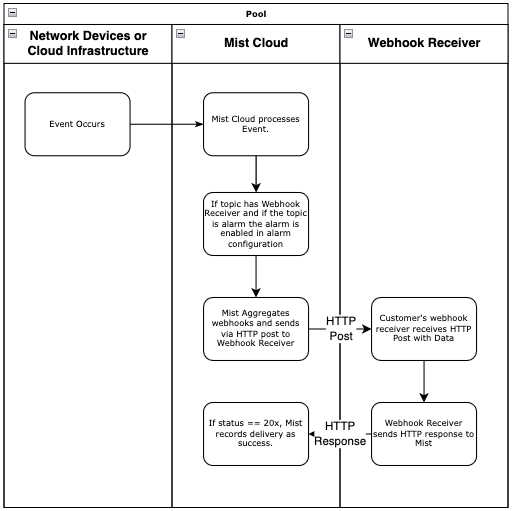
Webhook Data Flow
When you create a webhook, you subscribe to one or more topics. These topics contain events and when those events occur, your webhook receiver is sent those events via an HTTP Post.
Aggregation:
Mist will aggregate each topic, meaning that you will not receive a single webhook for each event that occurs. If multiple events for a given topic occur during the aggregation window, they will be grouped into a single message and sent.
Because of aggregation, you will need to split events when they are received, or have some way to deal with multiple events per message.
Webhook Hierarchy:
Webhooks can be configured from either the Organization level or the Site level. All webhooks are available at the site level.
Of those webhooks, the following topics are available at the org level:
- Alarms
- Audits
- device-events
- device-updowns
- client-session
- client-join
When planning for webhooks, it’s important to know that if you enable a webhook topic at both the site and organization level, you will receive duplicate webhooks.
Webhook Format:
Each topic of webhook can have slightly different formats. Most non-location webhooks have the following structure where the event details is the payload of the event.
{
"topic": "webhook-topic",
"events": [
{"EVENT DETAILS": "...."},
{"EVENT DETAILS": "....",
...
]
}Webhook Payloads:
Each webhook can have drastically different fields in the payloads. However, there are a number of fields that are pretty common in the alarms, device-events and audit topics we cover in this document.
{
"severity": "info",
"reason": [
"power_cycle"
],
"last_seen": "2022-03-01T21:57:08",
"aps": [
"d420aabbccd0",
"d420aabbccd1",
"d420aabbccd2",
"d420aabbccd3",
"d420aabbccd4",
"d420aabbccd5",
"d420aabbccd6",
"d420aabbccd7",
"d420aabbccd8",
"d420aabbccd9"
],
"org_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx1",
"site_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx2",
"count": 17,
"hostnames": [
"Hostname0",
"Hostname1",
"Hostname2",
"Hostname3",
"Hostname4",
"Hostname5",
"Hostname6",
"Hostname7",
"Hostname8",
"Hostname9"
],
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx3",
"type": "device_restarted",
"group": "infrastructure",
"timestamp": 1646172401.98089,
"site_name": "SiteName"
}- timestamp: this field is common across almost all webhooks. This is the epoch time in seconds when this payload occurred. You should use this instead of the time you received the webhook.
- site_name: this is the name of the site to which this payload is relevant. This is not present on every payload, but is on enough that it’s included here.
- site_id: the ID of the site to which this payload is relevant
- org_id: this is useful if you are managing multiple organizations, like large enterprises or MSPs will.
Webhook Topics:
Webhooks are broken down into topics. Each webhook you receive will contain events that are exclusively to that topic.
Alarms:
When it comes to monitoring Mist, Alarms is the first webhook topic you should be interested in. You can specify which alarms you are interested in the alert configuration (UI) / alarm template (api).
You may see the term alarm or alert used interchangeably. When the API was developed, the term used was alarm. During UI development, the term was changed to alert. These mean the same thing, and typically when referring to webhooks we refer to them as “alarms”
If you check the enable box next to an alarm, those will show up in the UI under alerts as well as sending webhook notifications for the alarm topic.
You can customize alarms/alerts per site using alarm templates.

Alarm Templates to specify which have which alarms enabled.
Alarms currently come in 3 types: Infrastructure, Marvis and Security. Each of these have some nuance to them that we’ll cover below.
You can pull which alarms are available and get examples of their payloads via the following API call: GET /api/v1/const/alarm_defs
Alarms – Infrastructure:
Infrastructure alarms don’t typically keep state. They are based directly off the device events. Monitoring devices off of infrastructure alarms, you would typically either treat each event as a standalone event, or you would match up stateful device changes.
You can configure some dampening of device_down alarms with to only notify when the device has been down for X minutes:

An example of determining state:
switch_offline would have a corresponding switch_reconnected event. This allows you to keep state for which switches are offline. However, events like switch_restarted indicates the switch rebooted (uptime reset to 0) and has no corresponding recovery event.
Note: When looking at a number of webhook infrastructure topics, the name
devicegenerally refers toAP. This has been left this way due breaking existing implementations if changed. Examples aredevice_down,device_reconnected,device_restarted. Some newer alarms (such as marvisap_offlinehave been named to reflect that these are APs.
Alarms – Marvis:
Marvis events are the events under Marvis Actions. These events are generally stateful. Inside the payloads there is a key called details. Under details you should see state and the values here are either open or validated. Open means this issue is currently happening, while validated means that Marvis has validated that the issue is resolved. Once the issue is deemed to be validated, the same webhook type will be set with the updated state.
Because of the AI nature of Marvis actions, marvis requires sufficient data to ensure that these alarms are accurate and actionable. Marvis needs accumulate enough data to eliminate false positives, resulting in variable amount of times for the events to arrive.
Alarms – Security:
Most of the events in security are single time events. We cannot tell if you an attack is no longer happening, but we can tell you when we detect specific attacks.
Rogue APs are rate-limited to reporting every 10 hours. Rogue Clients and Honeypot APs are sent every 10 minutes.
Alarm Payload common elements:
There are a number of elements that are common in alarm payloads. This does not encompass every field for every alarm, however it does cover the majority of
{
"severity": "info",
"last_seen": "2022-03-01T22:10:22",
"org_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx1",
"site_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx2",
"switches": [
"e8a2aabbccd0"
],
"count": 1,
"hostnames": [
"Hostname0"
],
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx3",
"type": "switch_reconnected",
"group": "infrastructure",
"timestamp": 1646172624.0424914,
"site_name": "SiteName"
}- severity: this is a pre-determined severity used by Mist. You may want to map each event to your own severity level inside your ITSM system.
- id: this is an event_id as this was processed through the alarm framework. It is not intended for you to try to correlate multiple webhooks with it.
- count: the number of times this particular event has occurred.
- aps, switches, gateways: Depending on the type of alert, these are the MAC addresses of the affected devices.
- hostnames: for the devices in the aps/switches/gateways field, these are the hostnames of the devices.
- group: this is the alarm group that the alarm belongs to. Currently the values are
infrastructure,marvisandsecurity.
- last_seen: this is the last time time this event was seen.
- type: this is the key for the type of alarm it is.
Device-Events
The device-events topic is specific to events that happen on devices (currently AP, Switch, Gateway). These are the raw events, so they can get fairly chatty (every time a port goes up/down, every time an AP changes channels/power, etc.
You can pull which device-events are available and get examples of their payloads via the following API call. Note, that not all events that occur here get sent via webhook.
GET /api/v1/const/device_events
Device-updowns
This topic is a subset of device events that only include the _disconnected, _reconnected, and _restarted events. This currently supports APs, Switches and Gateways (WAN Edges). If you use the device-events topic, you will receive duplicates of these events.
It is recommended to use
alarmsoverdevice-updowns, due to granular control of which type of devices on which sites (via alarm template) as well as thresholds for alerting.
Audits
This topic is designed to show that configuration changes were made to the Mist dashboard. You can use this to keep receive notifications to changes to the Mist configuration.
Configuring Webhooks
There are currently 2 ways of configuring webhooks, via the UI or the API.
Configuring via the UI:
You can configure webhooks in either the Organization > Settings, or in Organization > Site Configuration > Site. The configuration options should be the same, the only major difference is which webhook topics are available.
Under the Webhooks section you can click the Add Webhook button.

From here, you can specify the Name, URL and topics you want to subscribe to.

If you pick Webhook Type splunk you will need also provide the Splunk Token for HEC.
Advanced Settings:
Under the Show Advanced Settings there are a couple of options you can fill out.

- Verify Certificate allows you to disable Mist from verifying the certificate of the webhook receiver is valid. While this is not secure, it does provide some flexibility if your webhook receiver does not have a valid signed certificate. This is not recommended for security reasons.
- Secret (http-post only) allows you specify a secret used to calculate a pair of HTTP headers allowing you to validate the message is truly from mist and has not been modified. See image below for details
- Custom Headers allows you to specify any custom headers needed for your webhook receiver. This can allow you to present any customer HTTP header to your webhook receiver. Some receivers (or their proxies) can require token based authentication, user based authentication or a to present custom headers to indicate the type of data that is being sent. For restrictions, see image below.

Screenshot from API Documentation, custom headers and secret.
Update Webhooks via the UI:
You can modify existing webhooks by clicking on the entry for the webhook. The checkmark on the right should indicate if the webhook is enabled or not.

Configuring Webhooks via the API:
Given the two locations you can configure a webhook, each has their own API endpoint to configure a webhook.
You can find all the details for configuring webhooks at the following link: https://api.mist.com/api/v1/docs/Site#webhooks
API endpoints: Org-level webhook: /api/v1/orgs/:org_id/webhooks
Site-level Webhook: /api/v1/sites/:site_id/webhooks
Correlating events for device status
The first thing most organization want to monitor is for device status (up/down). There are multiple ways to do this, but we are going to focus on using Infrastructure alarms and then layer in things that provide additional context.
Monitoring Alarms: down/reconnected
The recommended way to monitor for device status is with the Alarms topic and the Infrastructure offline events. Specifically device_offline, switch_offline and gateway_offline.

Each of these UI elements actually encompass two alarms: _down and _reconnected per type of device. In the API, you can enable these separately if you desire. But these two form the basis of marking an AP as up or down.
Note: Just because an AP is disconnected does not necessarily mean it is not serving clients. We’ll address this in the Marvis section
Now for our generic Monitoring system (ITSM). In general, we’ll open an incident when we receive the device_down event and attach the APs for that alarm. When we receive the device_reconnected we will resolve the incident for the APs in that alarm.

When there are multiple APs in a single alarm, you can choose best how to handle this. This may be a single ITSM event for the entire incident, or it may be an incident per AP.
If you want to know how best to handle this, your ITSM contact is probably the person to ask, they should be able to steer you towards the method that works best with your monitoring system.
Adding contextual information from device_restarted
Now that we have our basic functions of automatically creating and resolving incidents with webhooks, let’s add some contextual information. For APs, if during their disconnection, they rebooted (uptime reset to 0) they will send a device_restarted alarm.

In the device_restarted alarm you should see a reason field. This field will give you some indication as to why the device restarted. When this webhook arrives, you can use the reason field to add context to the incident as to why it happened. For instance, if the site lost power, “power cycle” would be the reason code.

Taking this further, you can extend this incident with additional webhooks as needed.
Security Alarm Correlation:
When it comes to Security alarms, the “detected” model is sometimes hard for folks to open and resolve incidents in their ITSM software. To help with this, you will typically not use the detecting AP to group the events as you would for infrastructure alarms, as an ongoing attack can be seen and reported by multiple APs. Instead, it is often better to group these events by site_id or site_name . This way, multiple APs reporting the same attack at the same time can be correlated and grouped into a single incident, rather than an incident per AP.
Since there is no “recovery” event for this type of alarm, typically you will define a timeframe (24 hours as example) where if you see no further security events, you can consider the incident resolved.
